変換というと語弊があるのですが、以下の画像のようになっているテキストファイルがあります。
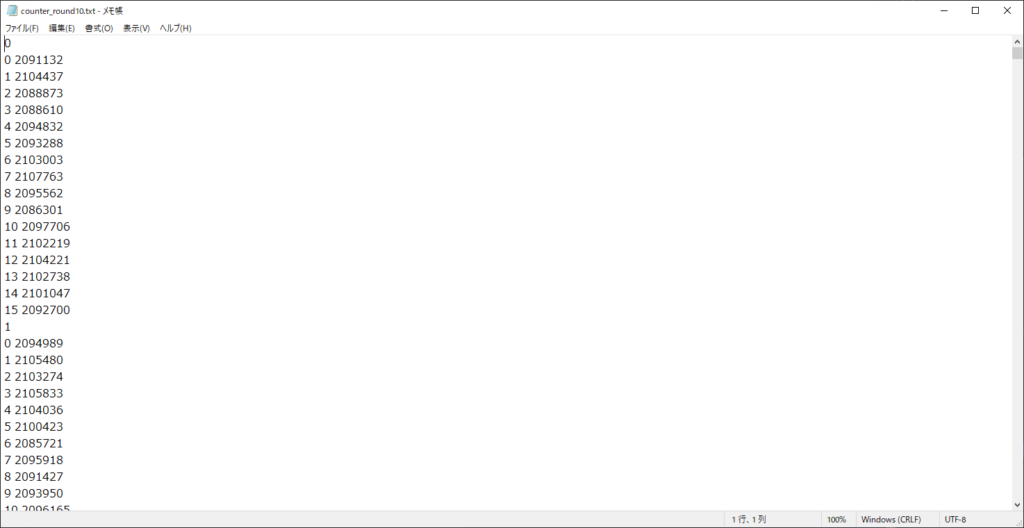
このテキストファイルを、次のようなxlsxファイルにしたいと思いました。
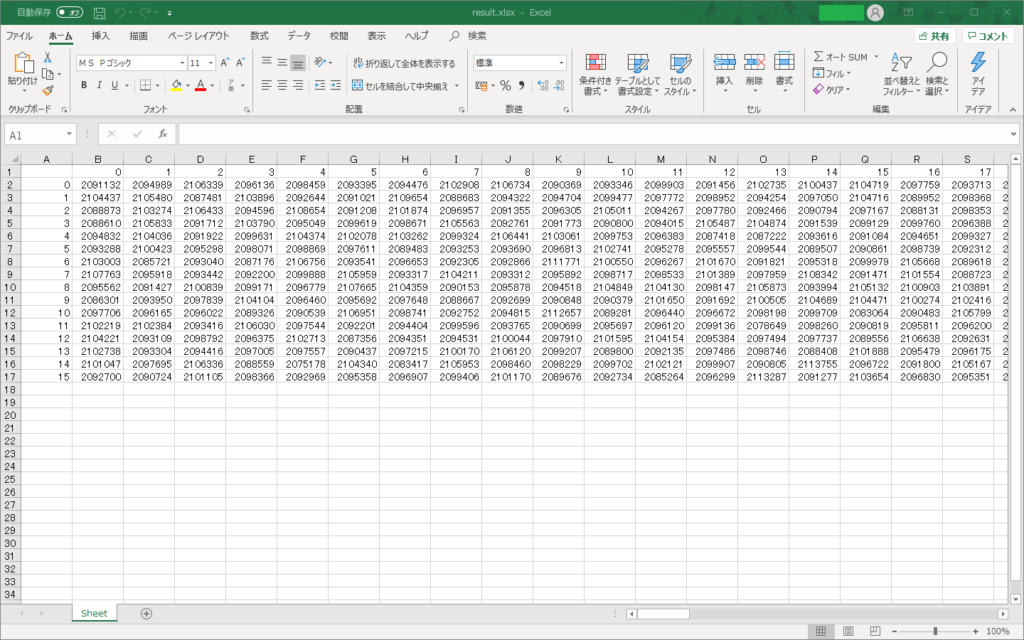
ということでpythonでコードを書いていきましょう。
さて、pythonのコードを書くわけですが、私はpython初心者です。コードを書き上げる数時間前にpythonに初めて触ったレベルなので、動くコードはかけましたが、きれいなコードは書けないのでご容赦ください。
書いたコード
書いたコードは以下のとおりです。
私の備忘録も兼ねて、どこをどのように調べてこのコードを書いたのか説明をしていきます。
import
[py] import openpyxl as px [/py]C/C++のincludeみたいなものなんですが、ちょっと違います。pythonは標準ライブラリがすでに読み込まれています。それも膨大な数です。
[blogcard url=”https://docs.python.org/ja/3/library/index.html”]
そのため、この標準ライブラリ外のモジュールをimportしていくわけです。
今回はxlsxファイルに出力するので、openpyxlというモジュールをインポートしています。
また、openpyxlは事前にインストールしておく必要があります。
インストール方法は、コマンドプロンプトを開いて、
[bash] pip install openpyxl [/bash]とコマンドを打てば大丈夫です。brewみたいに管理できるっぽくて驚いた。
as
ライブラリに好きな名前をつけられます。毎回openpyxlって書くのがめんどくさいので、pxという名前をつけています。
[blogcard url=”https://algorithm.joho.info/programming/python/import-as-from-py/”]
ファイル入力
[py] #ファイルを開く path = r"G:\atom\igarashi\counter_round10.txt" file = open(path) #すべての行をリストとして読み込み lines = file.readlines() #ファイルを閉じる file.close() [/py]絶対pathをpathという変数に代入します。この時、windows環境だとダブルクオーテーションマークの前にrを付ける必要があります。
[blogcard url=”https://cocodrips.hateblo.jp/entry/2015/07/19/120028″]
これがないと、「該当のファイルやディレクトリはありません」ってエラーが出ます。私はこれで30分ぐらい失いました。
次に、ファイルを開きます。open()関数を使って開けば終わりです。ここでオプションを指定することもできますが、デフォルトで”読み取り専用”なので、よほどのことがなければこのままでいいと思います。
さらに、ファイルを開いたらすべての行を読み込みます。いろいろな読み込み方があるそうですが、今回はすべての行をlistに入れていく方法を取りました。
[blogcard url=”https://note.nkmk.me/python-file-io-open-with/”]
最後に、ファイルを閉じます。withを使って書けばいらないらしいですが、私は書きました。
ブックを作成
[py] #ブックを新規作成。Workbookの’w’は必ず大文字。 wb = px.Workbook() [/py]ブックを新規作成します。Workbookのwは大文字じゃないとエラーが出ます。
シートを選択
[py] #アクティブなシートを取得 ws = wb.active [/py]アクティブなシートを選択します。他にも、シートを作成したりできます。
[blogcard url=https://note.nkmk.me/python-openpyxl-usage/”]
1列目に0~15を代入する
[py] #1行目に2列目から17列目まで1~15の値をセルに代入 for a in range(1, 17): ws.cell(row=a+1, column=1).value = a-1 [/py]上にあるExcelのスクショのA列のようにしたかったので、こういう書き方をしました。
rowは行で、columnは列です。間違えないようにしましょう。私は間違えて1時間を失いました。
for文
ただのfor文ですが、C++と大きく異なったものでした。
C++でfor文を書くと、
[cpp] for(int i = 0; i < 10; i++){ //処理 } [/cpp]のようになります。一番最初に習う形です。
for(初期化式; 条件式; 増減式)の順に書きます。C++03まではこうでしたが、C++11からはもっとスマートな書き方ができるらしいのを今知った。
[blogcard url=”https://cpprefjp.github.io/lang/cpp11/range_based_for.html”]
それはさておき、pythonではfor文を、
for 変数 in データの集合
というふうに書きます。この時点でC++とは大きく違います。
C++の感覚で行くと、inの後ろはbeginとendを指定するものだと思います。しかし、ここにあるのは”データの集合”であって、条件式ですらありません。なので、この部分にrange()を置くこともあれば、stringを置くこともあれば、listを置くこともあります。
そのため、文字列から一文字ずつ取り出すときは、C++なら
[cpp] string s = "Hello"; for(int i = 0; i < 5; i++){ cout << s[i] << endl; } [/cpp]と書きますが、pythonなら
[py] for char in ‘Hello’: print(char) [/py]で終わりです。いや、charという変数を使えるのすら驚きなんですけど。
コードの参考:
[blogcard url=”https://qiita.com/Morio/items/e8aed85346c0055beea7″]
ということで、現時点で私は、”データの集合”のsizeの分だけループが周り、変数には”データの集合”から取り出された値が代入されていると解釈しています。正しいのかはわからん。
for文一つとってもC++と違いすぎて、頭を抱えていました。
splitしてcellに書き込む
[py] #listを取得するための変数 l = 0 #セルへの書き込み for i in range(2,130): for j in range(1,18): blank = lines[l].split() ws.cell(row=j, column=i).value = int(blank[len(blank)-1]) l += 1 [/py]pythonのfor文に慣れていないので、C++で書くような感じで書きました。
ここでは、C++には無いsplit関数を使います。C++はsplit関数を自分で作らないとダメです。区切り文字で区切って返すぐらいならgetline関数使えばすぐに作れるんですけど。
さて、splitですが、返り値はリストになります。
[blogcard url=”https://note.nkmk.me/python-split-rsplit-splitlines-re/”]
この箇所が一番つまずいた部分です。
一番上のtxtファイルのスクショでは、1行目は0のみ、2行目以降は”0 2091132″というふうにスペースで区切りが入ってます。
そのため、1行目をsplitすると、0のみが入った要素数1のlistが戻り値となります。
しかし、2行目以降をsplitすると、0と2091132が入った要素数2のlistが戻り地となります。
この要素数の差が曲者で、もともと以下のように書いていました。
[py] if j == 0: ws.cell(row=j,column=i).value=int(blake[0]) else: ws.cell(row=j,column=i).value=int(blake[1]) [/py]0行目なら1要素しかないので、listの1番目を取ってくる。それ以降なら2要素なのでlistの2番目を取ってくる、としたわけです。
しかし、このような書き方をすると、out of rangeとエラーが出ます。
どうやら、elseの方も一応評価されているっぽいです。よくわからんけど。
悩んだ挙げ句、最終的にlistの要素数が変わるんだから、要素数-1なら行けるんじゃね?ってことで、こうなりました。苦肉の策です。
len()
オブジェクトのサイズを取得できます。
[blogcard url=”https://note.nkmk.me/python-len-usage/”]
int()
intといえば整数型なんですが、なんとpythonでは関数にあります。
[blogcard url=”https://docs.python.org/ja/3/library/functions.html#int”]
機能はC++でいうstring_to_intと同じです。最初見たときは、「型キャストでいけるんか~」と思っててましたが、まさかの関数。世界が違う。
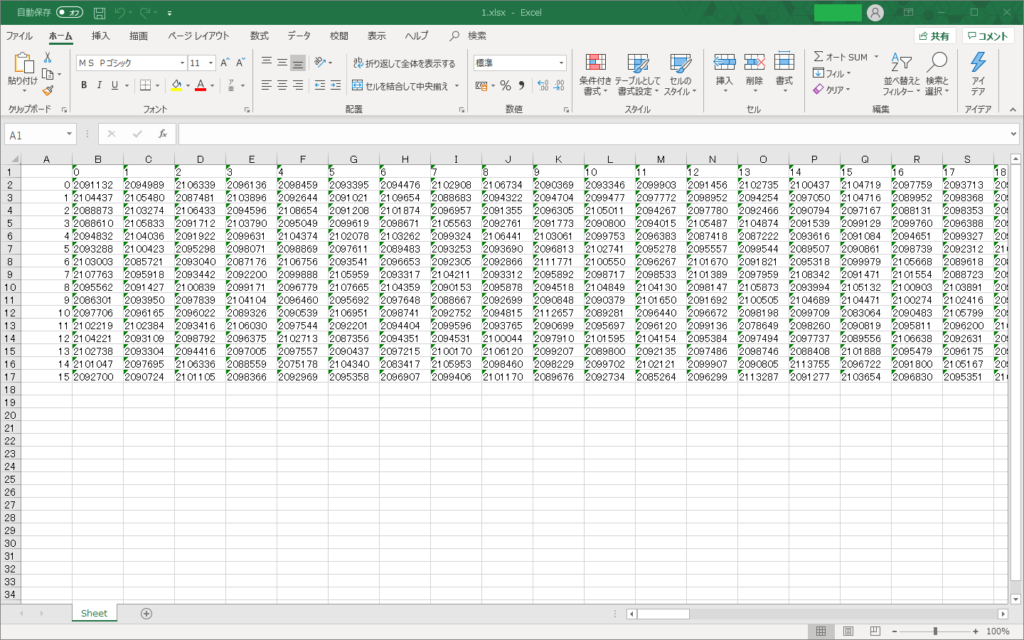
これは最後に付け加えた部分なのですが、このままセルに書き込むと文字列として書き込まれます。
その結果、次のようになったので、文字列を整数型に変換してから書き込むようにしました。Excelないでも文字列を数列にできるんですが、いちいちやるのがめんどくさいので、書き込む前に整数型に変換しました。
ブックを保存する
[py] #ブックを保存する wb.save(filename) [/py]ブックを保存して終わりです。
おわり
いつもC++を書いていたので、pythonのコードを書いている時に違和感しか感じませんでした。便利だなあと思う部分もあれば、これでいいのかってなる部分もありました。
chachaをC++で実装してるときに、pythonのコードを参考にさせてもらったこともありましたが、やはりpythonも書けないとダメだなあと思いました。
卒論終わったらpythonとRustを学んでみようかと思っています。
参考にさせていただいて、txtから空白を含むリストをエクセルに書き込めました。ありがとうございます。